This post continues the series of highlights from our recent BlackHat USA 2017 talk. An index of all the posts in the series is here.
Introduction
Before today’s public clouds, best practice was to store logs separately from the host that generated them. If the host was compromised, the logs stored off it would have a better chance of being preserved.
At a cloud provider like AWS, a storage service within an account holds your activity logs. A sufficiently thorough compromise of an account could very well lead to disrupted logging and heightened pain for IR teams. It’s analogous to logs stored on a single compromised machine: once access restrictions to the logs are overcome, logs can be tampered with and removed. In AWS, however, removing and editing logs looks different to wiping logs with rm -rf.
In AWS jargon, the logs originate from a service called CloudTrail. A Trail is created which delivers the current batch of activity logs in a file to a pre-defined S3 bucket at variable intervals. (Logs can take up to 20 mins to be delivered).
CloudTrail logs are often collected in the hope that should a breach be discovered, there will be useful audit trail in the logs. The logs are the only public record of what happened while the attacker had access to an account, and form the basis of most AWS defences. If you haven’t enabled them on your account, stop reading now and do your future self a favour.
Prior work
In his blog post, Daniel Grzelak explored several fun consequences of the fact that logs are stored in S3. For example, he showed that when a file lands in an S3 bucket, it triggers an event. A function, or Lambda in AWS terms, can be made to listen for this event and delete logs as soon as they arrive. The logs continue to arrive as normal (except for the logs evaporating on arrival.)
 |
| Flow of automatic log deletion |
Versions, lambdas and digests
Adding “versioning” to S3 buckets (which keeps older copies of files once they are overwritten) won’t help, if an attacker can grant permission to delete the older copies. Versioned buckets do have the option of having versioned items protected from deletion by multi-factor auth (“MFA-delete”). Unfortunately it seems like only the AWS account’s root user (as the sole owner all S3 buckets in an account) can configure this, making it less easy to enable in typical setups where root access is tightly limited.
In any case, an empty logs bucket will inevitably raise the alarm when someone comes looking for logs. This leaves the attacker with a pressing question: how do we erase our traces but leave the rest of the logs available and readable? The quick answer is that we can modify the lambda to check every log file and delete any dirty log entries before overwriting them with a sanitised log file.
But a slight twist is needed: when modifying logs, the lambda itself generates more activity which in turn adds more dirty entries to the logs. By adding a unique tag to the names of pieces of the log-sanitiser (such as name of the policies, roles and lambdas), these can be deleted like any other dirty log entries so that the log-sanitiser eats it’s own trail. In this code snippet, any role, lambda or policy that includes thinkst_6ae655cf will be kept out of the logs.
That would seem to present a complete solution, except that AWS Cloudtrail also offers log validation (aimed specifically at mitigating silent changes to logs after delivery). At regular intervals, the log trail delivers a (signed) digest file that attests to the contents of all the log files delivered in the past interval. If a log file covered by the digest changes, that digest file validation fails.
 |
| A slew of digest files |
At first glance this stops our modification attack in its tracks; our lambda modified the log after delivery, but the digest was computed on the contents prior to our changes. So the contents and the digest won’t match.
Also covered by each digest file, is the previous digest file. This creates a chain of log validation starting at the present and going back up the chain into the past. If the previous digest file has been modified or is missing, the next digest file validation will fail (but subsequent digests will be valid.) The intent behind this is clear: log tampering should show that AWS command line log validation shows an error.
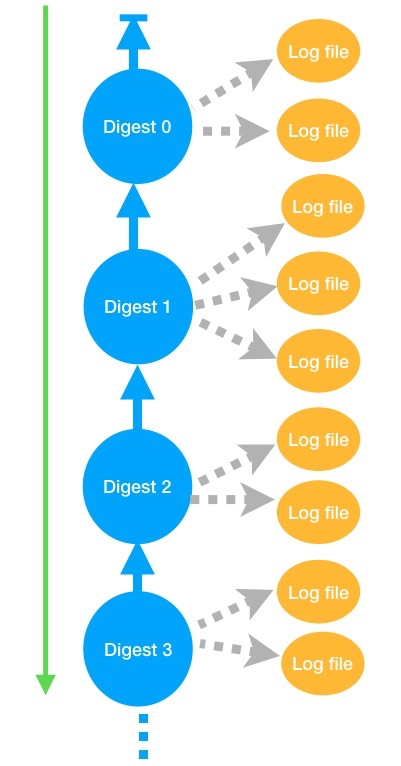 |
| Chain of digests and files they cover |
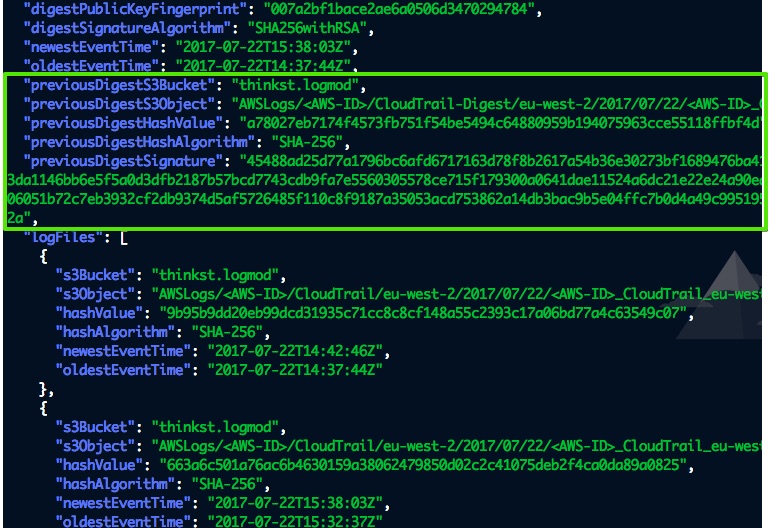 |
| Contents of a digest file |
It would seem that one option is to simply remove digest files, but S3 protects them and prevents deletion of files that are part of an unbroken digest chain.
There’s an important caveat to be aware of though: when log validation is stopped and started on a Trail (as opposed to stopping and starting the logging itself), the log validation chain is broken in an interesting way. The next digest file that is delivered doesn’t refer to previous digest file since validation was stopped and started. Instead, the next digest file references null as its previous file, as if it’s a new digest chain starting afresh.
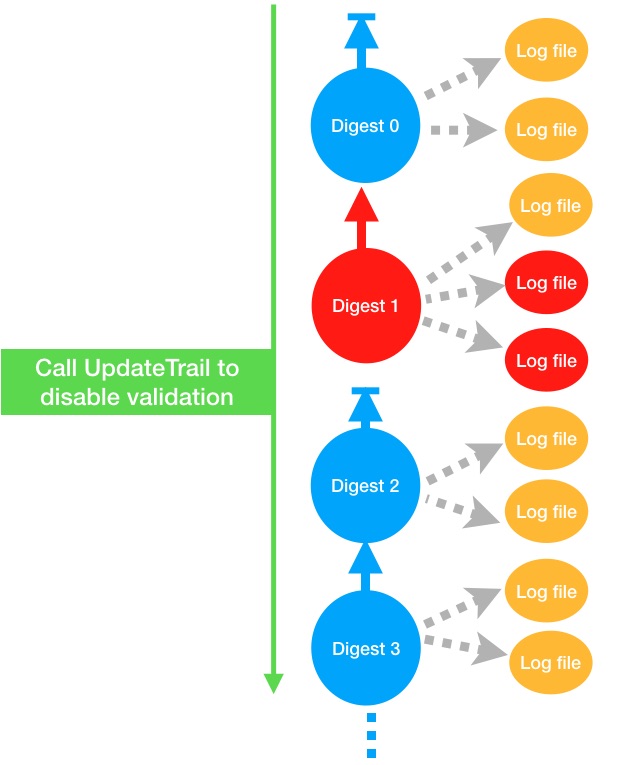 |
| Digest file (red) that can be deleted following a stop-start |
In the diagram above, after the log files in red were altered, log validation was stopped and started. This broke the link between digest 1 and digest 2.
Altered logs, successful validation
We said that S3 prevented digest file deletion on unbroken chains. However, older digest files can be removed so long as no other file refers to them. That means we can delete digest 1, then delete digest 0.
What this means is that on the previous log validation chain, we can now delete the latest digest entry file without failing any digest log validation. The log validation will start at the most recent chain, and move back up. When the validation encounters the first item on the previous chain, it simply moves on to the latest available item of the previous chain. (There may be a note about no log files being delivered for a period, but this is the same message that arrives when no log files are delivered as well.)
 |
| No complaints validity complaints about missing digest files |
And now?
It’s easy to imagine that log validation is simply included in automated system health-checks; so long as it doesn’t fail, no one will be verifying logs. Until they’re needed, of course, at which point the logs could have been changed without validation producing an error condition.
This attack signature is: validation was stopped and started (rather than logging being stopped and started). It underscores the importance of alerting on CloudTrail updates, even if it doesn’t stop logging. (One way would be to alert on UpdateTrail events using the AWS CloudWatch service.) A single validation stop and start event, means it is not a safe to assume that the AWS CLI tool reporting that all logs validate means that the logs haven’t been tampered with. The log validation should be especially suspect if there are breaks in the digest validation chain, which would have to be manually verified.
Much like in the case of logs stored on a single compromised host, logs should be interpreted with care when we are dealing with compromised AWS accounts that had the power to alter them..