Security vendors have a mediocre track record in keeping their own applications and infrastructure safe. As a security product company, we need to make sure that we don’t get compromised. But we also need to plan for the horrible event that a customer console is compromised, at which point the goal is to quickly detect the breach. This post talks about how we use Linux’s Audit System (LAS) along with ELK (Elasticsearch, Logstash, and Kibana) to help us achieve this goal.
Background
Every Canary customer has multiple Canaries on their network (physical, virtual, cloud) that reports in to their console which is hosted in AWS.
Consoles are single tenant, hardened instances that live in an AWS region. This architecture choice means that a single customer console being compromised, won’t translate to a compromise of other customer consoles. (In fact, customers would not trivially even discover other customer consoles, but that’s irrelevant for this post.)
Hundreds of consoles running the same stack affords us an ideal opportunity to perform fine grained compromise detection in our fleet. Going into the project, we surmised that a bunch of servers doing the same thing with similar configs should mean we can detect and alert on deviations with low noise.
A blog post and tool by Slack’s Ryan Huber pointed us in the direction of the Linux Audit System. (If you haven’t yet read Ryan’s post,
you should.)
LAS has been a part of the Linux kernel since at least 2.6.12. The easiest way to describe it is as an interface through which all syscalls can be monitored. You provide the kernel with rules for the things you’re interested in, and it pushes back events every time something happens which matches your rules. The audit subsystem itself is baked into the kernel, but the userspace tools to work with it come in various flavours, most notably the official “
auditd” tools, “
go-audit” (from Slack) and
Auditbeat (from Elasticsearch).
Despite our love for Ryan/Slack, we went with Auditbeat mainly because it played so nicely with our existing Elasticsearch deployment. It meant we didn’t need to bridge syslog or logfile to Elastic, but could read from the audit Netlink socket and send directly to Elastic.
From Audit to ELK
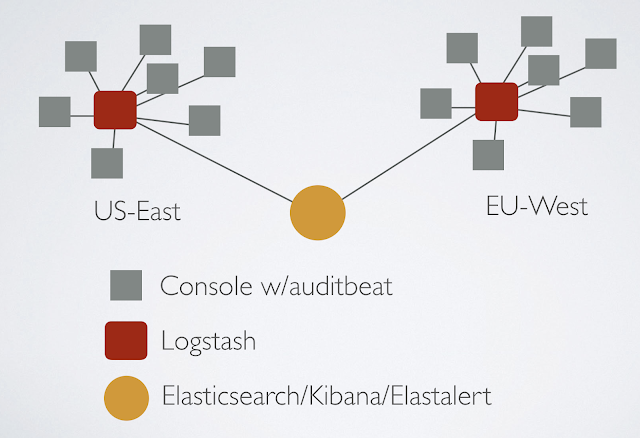
Our whole set-up is quite straightforward. In the diagram below, let’s assume we run consoles in two AWS regions, US-East-1 and EU-West-2.
We run:
- Auditbeat on every console to collect audit data and ship it off to Logstash;
- A Logstash instance in each AWS region to consolidate events from all consoles and ship them off to Elasticsearch;
- Elasticsearch for storage and querying;
- Kibana for viewing the data;
- ElastAlert (Yelp) to periodically run queries against our data and generate alerts;
- Custom Python scriptlets to produce results that can’t be expressed in search queries alone.
So, what does this give us?
A really simple one is to know whenever an authentication failure occurs on any of these servers. We know that the event will be linked to PAM (the subsystem Linux uses for most user authentication operations) and we know that the result will be a failure. So, we can create a rule which looks something like this:
auditd.result:fail AND auditd.data.op:PAM*

What happens here then, is:
- Attacker attempts to authenticate to an instance;
- This failure matches an audit rule, is caught by the kernel’s audit subsystem and is pushed via Netlink socket to Auditbeat;
- Auditbeat immediately pushes the event to our logstash aggregator;
- Logstash performs basic filtering and pushes this into Elasticsearch (where we can view it via Kibana);
- ElastAlert runs every 10 seconds and generates our alerts (Slack/Email/SMS) to let us know something bad(™) happened.
Let’s see what happens when an attacker lands on one of the servers, and attempts to create a listener (because it’s 1999 and she is trying a bindshell).
In 10 seconds or less we get this:
which expands to this:
From here, either we expect the activity and dismiss it, or we can go to Kibana and check what activity took place.
Filtering at the Elasticsearch/ElastAlert levels gives us several advantages. As Ryan pointed out), keeping as few rules / filters on the actual hosts, leaves a successful attacker in the dark in terms of what we are looking for.
Unknown unknowns
ElastAlert also gives us the possibility of using more complex rules, like “
new term”.
This allows us to trivially alert when a console makes a connection to a server we’ve never contacted before, or if a console executes a process which it normally wouldn’t.
Running auditbeat on these consoles also gives us the opportunity to monitor file integrity. While standard audit rules allow you to watch reads, writes and attribute changes on specific files, Auditbeat also provides a file integrity module which makes this a little easier by allowing you to specify entire directories (recursively if you wish).
This gives us timeous alerts the moment any sensitive files or directories are modified.
Going past ordinary alerts
Finally, for alerts which require computation that can’t be expressed in search queries alone we use Python scripts. For example, we implemented a script which queries the Elasticsearch API to obtain a list of hosts which have sent data in the last n-minutes. By maintaining state between runs, we can tell which consoles have stopped sending audit data (either because the console experienced an interruption or because Auditbeat was stopped by an attacker.) Elasticsearch provides a really simple REST API as well as some powerful aggregation features which makes working with the data super simple.
Operations
Our setup was fairly painless to get up and running, and we centrally manage and configure all the components via SaltStack. This also means that rules and configuration live in our regular configuration repo and and that administration overhead is low.
ELK is a bit of a beast and the flow from hundreds of Auditbeat instances means that one can easily get lost in endless months of tweaking and optimizing. Indeed, if diskspace is a problem, you might have to start this tweaking sooner rather than later, but we optimized instead for “shipping”. After a brief period to tweak the filters for obvious false positives, we pushed into production and our technical team pick up the audit/Slack alerts as part of our regular monitoring.
Wrapping up
It’s a straightforward setup, and it does what it says on the tin (just like Canary!). Combined with our other defenses, the Linux Audit System helps us sleep a little more soundly at night. I’m happy to say that so far we’ve never had an interrupted night’s sleep!