- It seemed like a lot of drudgery for something we have been able to do well without,
- It steers towards the word “taxonomy” [1]
- I was a little lazy.
[1] Dave Aitel has posited that “people who thing (sic) of things as “Taxonomies” are always
headed in the opposite direction from correct”
Late last year i ran some scripts (and waded) through OSVDB’s database, to see if we could pull through some numbers on memory corruption bugs (through the ages) and their disclosure rate compared to other bugs. (theres actually a wealth of fiddling in these numbers too, that ill get around to at some point).
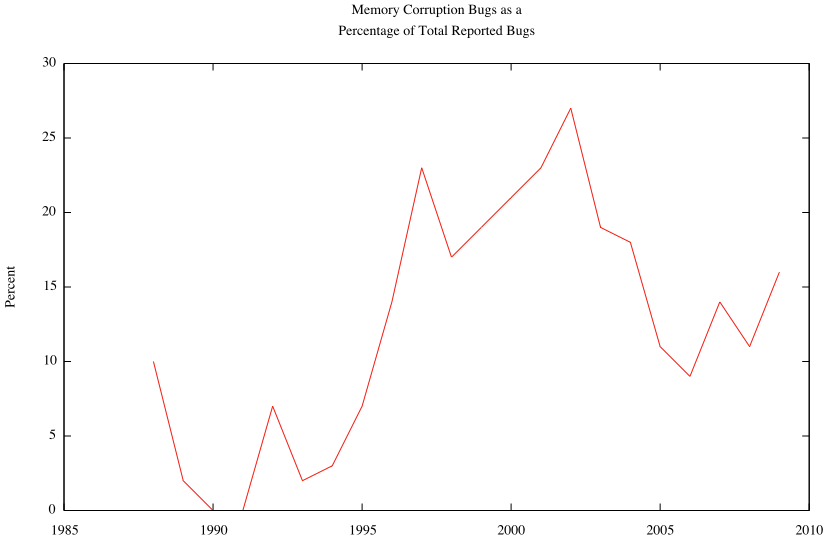
I figured it would be nice to see a timeline of memory corruption exploitation techniques along with the mitigation steps introduced plotted along-side the bug counts (but still lacked the real motivation).
Late last year, HalVar tweeted
“Walking down memory lane, reading old exploits from ’99 — can someone write a history of code exec ’95-2009 ?”
@benhawkes did a fine job of presenting this at kiwikon, and over the years a few people have written papers / done presentations which covered some of this ground [A brief history of Exploitation Techniques and Mitigations on Windows][Generic Anti-Exploitation Technology for Windows][A Comparison of Buffer Overflow Prevention Implementations and Their Weaknesses].
The recent “Return Oriented Programming” / advanced ret-2-libc discussions revived these chats.
The incomparable @silviocesare said:
“A text file on google is transient, not officially archived, and generally academically untrustworthy.” and “..Citing a URL which will be offline in 10 years time is not good.”
This is true, but tragic if it means that techniques discovered in the 90’s are not credited when re-introduced into academia today..
or as Halvar said
“The ROP discussion is amusing in the sense that our folklore gets republished, and then we are asked “what papers have you published” ? :)”
Being a closet academic (or at least trying to look like one), it seems the natural thing to do then is to actually see if we can get a good handle on our “folklore“. Im hoping that if we can add a reasonable amount of rigor, it can also pass as academically submittable ensuring that its read into the rolls..
Tim Kornau over at Zynamics waded through some of the history in his
post on return-oriented programming and prefaced his post with the following disclaimer: “I will also take some of the recent discussions on Twitter into account which showed that even though I thought I did my history research pretty well, there were still some mailing list post missing from my time-line.”
It’s clear that doing this alone will miss huge chunks of data (and no doubt offend some people terribly). The simple answer is to experiment with a buzz-word, and try to “crowd-source” it.
I have put up a simple google-doc spreadsheet, which ties back to the eye candy visualizations you can see here: [index] and here: [combo]
(The combo page uses a Google visualization that needs flash, so you can skip it)
The important bit however is this.. Use the form to add events that you think need adding.. If you have it with a good link and/or reference, thats perfect, but even if you dont, add it anyway.. Our budding group of eager researchers (me), will chase it down and make sure its slotted in the right place.