Introduction
Today we’re open-sourcing a research project from Labs, ZipPy, a very fast LLM text detection tool. Unless you’ve been living under a rock (without cellphone coverage), you’ve heard of how generative AI large language models (LLMs) are the “next big thing”. Hardly a day goes by without seeing a breathless article on how LLMs are either going to remake humanity, or bring upon its demise; this post is neither, while we think there are some neat applications for LLMs, we doubt it’s the end of work or humanity. LLMs do provide the ability to scale natural language tasks, for good or ill, it is when that force-multiplier is used for ill, or without attribution, that it becomes a concern already showing up, from disinformation campaigns, cheating in academic environments, or automating phishing; detecting LLM-generated text is an important tool in managing the downsides.
There are a few LLM text classifiers available, the open-source Roberta-base-openai-detector model, GPTZero, and OpenAI’s detector. All of these have shortcomings: they are also large models trained on large datasets, and the latter two are commercial offerings with little information on how they operate or perform. ZipPy is a fully open-source detector that can be embedded into any number of places, enabling detection “on the edge”.
TL:DR; ZipPy is a simple (< 200 LoC Python), open-source (MIT license), and fast (~50x faster than Roberta) LLM detection tool that can perform very well depending on the type of text. At its core, ZipPy uses LZMA compression ratios to measure the novelty/perplexity of input samples against a small (< 100KiB) corpus of AI-generated text—a corpus that can be easily tuned to a specific type of input classification (e.g., news stories, essays, poems, scientific writing, etc.).
We should note that no detection system is 100% accurate, ZipPy included, and it should not be used to make high-consequence determinations without corroborating data.
Background
Generative AI and LLMs
LLMs are statistical machine learning (ML) models with millions or billions of parameters, trained on many gigabytes or terabytes of training input. With the immense volume of input data, during the training phase the model aims to build a probability weighting for all tokens or words given the preceding context. For example, if you were to read the contents of the entire web, the sentence “The quick brown fox jumps over the lazy dog” would [relatively] frequently. Given the context “The quick brown”, the most probable next word is learned to be “fox”. LLMs have to be trained on large datasets in order to attain the “magical” level of text understanding, and this requirement leads to our detection strategy.
Intuitively, every person has a unique vocabulary, style, and voice—we each learned to communicate from different people, read different books, had different educations. An LLM by comparison has the most probable/average style, being trained on close to the entire internet. This nuance is how LLM classifiers work—text written by a specific human will be more unique than the LLM’s model average human writer. The detectors listed above work by either explicitly or implicitly (through training on both human and LLM datasets) trying to determine how unique a text is. There are two common metrics, Perplexity and Burstiness.
Perplexity is a measure of surprise encountered with reading a text. Imagine you had read the entire internet and knew the probability tables for each word given the preceding context. Given “The quick brown” as context, and the word “fox”, there would be a low perplexity as the chance of seeing “fox” come next is high. If the word was instead “slug”, that would have a large difference between expectations and reality, so the perplexity would increase. The challenge with calculating perplexity is that you have to have a model of all language in order to quantify the probability of the text. For this reason, the existing detectors use large models trained on either the same training data as is used to train the LLM generators, or datasets of both human and LLM generated texts.
Burstiness is a calculation of sentence lengths and how they change throughout a text. Again, an LLM will generally migrate towards the mean, so lengths will be closer to the average, with human-written text having more variance in sentence length. This is easier to calculate, but more impacted by the type of text: some poems have little to no punctuation, whereas others have a number of highly uniform stanzas; news briefs are commonly punchier; and academic papers (and blogs about burstiness) can have extremely long sentences.
Both of these metrics are impacted by the temperature parameter used by an LLM to determine how much randomness to include in generation. Higher temperatures will be more perplexity and bursty, but run the risk of being more non-sensical to a human reader. If a human author is writing a summary of a local slug race, captioning a picture: “The quick brown slug, Sluggy (left), took home the gold last Thursday” would make sense. LLMs don’t understand the world or what they are writing, so if the temperature were set high enough that it would output: “The quick brown slug”, the rest of the text would likely be nonsensical.
Compression
Compression is the act of taking data and making it smaller, with a matched decompression function that returns the compressed data to [close to] the original input. Lossless compression (e.g., .ZIP files) ensures that the data post compression and decompression is the same as the original input; lossy compression (e.g., .JPG or .MP3 files) may make minor adjustments for better compression ratios. Compression ratios are a measure of how much smaller the compressed data is than the original input. For the remainder of this blog post we’ll just be discussing lossless compression.
Compression generally works by finding commonly repeated sequences and building a lookup table or dictionary. A file consisting of all one character would compress very highly, whereas truly random data would compress more poorly. Each compression algorithm may have different scheme for choosing which sequences to add to the table, and how to efficiently store that table, but generally they work on the same principles.
Compression was used in the past as a simple anomaly detection system: by feeding network event logs to a compression algorithm and measuring the resultant compression ratio, the novelty (or anomaly) of the input could be determined. If the input changes drastically, the compression ratio will decrease, alerting to anomalies, whereas more of the same background event traffic will compress well having already been included in the dictionary.
Implementation
ZipPy is a research tool that uses compression to estimate the perplexity of an input. With this estimation, it is possible to classify a text’s source in a very efficient manner. Similar to the network event anomaly model, ZipPy looks for anomalies in the input when compared to a [relatively] large initial input of AI-generated text. If the compression ratio improves when the sample is compressed, the perplexity is low as there are existing dictionary entries for much of the sample, whereas a high-perplexity input would reduce the ratio.
ZipPy starts with a body of text, all generated by LLMs (GPT, ChatGPT, Bard, and Bing) and compresses it with the LZMA compression algorithm (the same as in .ZIP files), calculating the ratio = compressed_size / original_size. The input sample is then appended to the LLM-generated corpus and compressed again with the new ratio computed the same way. If the corpus compresses worse than with the sample, then the sample is likely to be LLM-generated; if the compression ratio decreases, then the sample is more perplexity, and is more likely human-generated.
At its core, that’s it! However, as part of our research, there are a number of questions we’ve been exploring:
- How does the compression algorithm change the performance?
- What about compression presets (which improve compression but are slower)
- What is the optimal size and makeup of the initial body of AI-generated text?
- Should the samples be split into smaller pieces?
- Is there a minimum length of sample that can impact the overall ratio enough to get good data?
- How should formatting be handled? An early test on a human sample failed because each line was indented with 8 spaces (which compressed well).
We don’t have all the answers yet, but our initial findings are promising!
Evaluation
In order to test how well ZipPy performs, we needed datasets of both human and LLM text. In addition to using ChatGPT, Bard, and Bing to generate about ~100 new samples to test, we explored the following datasets:
OpenAI’s GPT-2 dataset (webtext and xl-1542M)
MASC 500k (excluding the email and twitter collections)
GPT-2-generated academic abstracts
News articles re-written by ChatGPT
CHEAT (ChatGPT-generated academic abstracts)
ZipPy performs best on datasets that are English (due to all of the AI-generated “training” text being English-language) and that are written as sensical prose. Two of the datasets we evaluated, GPT-2 and GPT-3 output were created without prompts to guide the output. ZipPy performs poorly on these, as the output is either poor (difficult to understand as a human) and/or extremely diverse (multiple languages, code, and odd formatting). A few examples from these datasets are provided below to provide a sense of the data that is difficult to classify for ZipPy:
layout_container:Genotion 2 – HD select
Focus: Batsu
Most more much HD contains information about is one of the best addon…read more Posts: 7
Check out more from Christina at: stock666.com Posted by:| September 03, 2018 06:36 AM design3D 2-3-3-3 … Posted by:| September 03, 2018 06:05 AM hiszog 2-3-3-3 … Posted by:| September 03, 2018 05:27 AM too amateur. At boot it says DLL missing. Posted by:| September 03, 2018 04:12 AM likes2eat 4-3-3-3 Early Review andenjoy! Posted by:| September 03, 2018 05:54 AM AutoVR 2-3-3-3 Built Dutch : O Posted by:| September 03, 2018 05:30 AM looks like it will get more popular : o Posted by:| September 03, 2018 02:10 AM Cross Fitness 3.0 Part 1 by CrossFit up
OpenAI GPT-2 sample #1
Convocainftvalerie 20
13.9” L Y
1107g
With Screen Case
Material: Acetate
Auction Location:
10360 W. San Ramon Fairgrounds, Sonoma, California, 94950, United States
Taxes: TAXES MAY APPLY
Buyer’s Premiums: From (Incl.) To (Excl.) Premium 0.00 Infinite 20%
Shipping Details:
There if be 3 Methods to Buy from the Big T: (1) eTailer, Ebay or other Auction Sites, or (2) Ebay (convention). This Year Auction Will be Conducted on Ebay.com
OpenAI GPT-2 sample #2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399…1280
OpenAI GPT-3 sample #1
Někdy mi začne zazvonit v telefonu život, protože to vůbec není telefon, ale sekundární vlna, kterou jsem přivolala k sobě.
Dnes mi to začalo zazvonit už po desáté, mám ráda pravidelnost, abych se v ní vyznala, a začala se pohybovat rychleji.
Ne, nemůžete se najít v mém životě, ale nemusíte také.
Protože se mi začne zazvonit, pořád stejně krásně, v okamžiku, když to přijde.
A je to pro vás taky tak nějak to pravé.
-Nekončí se už zase?- zaslechla jsem vyslovené základní já, a snažila jsem se mu na to odpovědět.
Nemáte moc důvodů mě zastrašovat, nebo mi přerušovat. Vy jste větší zvíře. Můžete si mě zavolat, když vám bude zase chybět něco vážnějšího. Nechcete to zas vyhodit, jako každého docela rozumného a slušného kluka, nebo jak jejich říkáte.
Komentáře
OpenAI GPT-3 sample #2
With a subset of at most 500 samples per included dataset, we run just under 5000 documents through ZipPy (2m14s), OpenAI’s detector (29m22s), Roberta (1h36m17s), and GPTZero (1h1m39s). From this data, we construct a ROC curve for each. ROC curves show both the accuracy (area under the curve, or AUC) as well as the sensitivity at different decision thresholds. All the detectors provide a confidence score that a sample is either AI or human-generated, if the threshold for the decision boundary is adjusted, the detector may detect more true positives, but at the expense of more false positive detections.
If the un-prompted datasets are excluded, the performance of the detectors gives the following ROC curve, with LZMA being the curve for ZipPy:

In simple terms, this curve shows that ZipPy correctly classifies the origin of an input 82% of the time, whereas Roberta has 80% accuracy, and both GPTZero and OpenAI sit at only 62% accurate. Adding the GPT-3 samples back in (without adding any new samples to the “training” file), the performance drops for ZipPy, and slightly improves for Roberta, which was trained on GPT datasets:
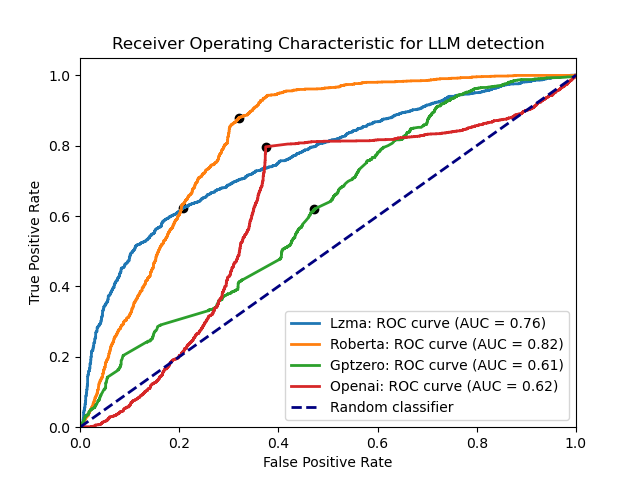
This shows that ZipPy’s compression-based approach can be accurate, but is much more sensitive to the type of input than Roberta. As ZipPy is more of an anomaly detector than a trained model, it cannot differentiate between novel types of input as well as the larger models. It does appear able to handle different types of data that have been added to the training file, the same data is used for news, essays, abstracts, forum posts, etc. but not completely differently formatted texts or those not in the same language as the training data. Additionally, due to the simple implementation, it is comparably easy to customize ZipPy for a specific set of inputs: simply replace the training file with LLM-generated inputs those that more closely the type of data to be detected.
It is interesting to see how poor the performance is from both OpenAI’s and GPTZero’s detectors, they are the commercial, closed-source options. That OpenAI’s detector should perform so poorly on datasets that presumably they would have easy access to is curious, hopefully as they improve their models their performance will catch up with the open-source Roberta model.
Conclusion
In conclusion, we think that ZipPy can add utility to workflows handling data of unknown origin. Due to its size, speed, and tunability, it can be embedded into a host of places where a 1.5B parameter model (Roberta) couldn’t. In the GitHub repository is: a Python 3 implementation of ZipPy, a Nim implementation that compiles to both a binary and a web-based detector, all of the data tested on, and harnesses for testing ZipPy and the other detectors.
As a cute example of how this could be used, we also include a browser extension that uses ZipPy in a web worker to set the opacity of web text to the confidence it is human-written. While there is too much diversity to the style of text in an average day’s browsing session, it demonstrates a proof-of-concept for filtering out the LLM-generated noise.
We are still actively exploring this idea, and would love feedback or thoughts. If you’d like to collaborate with us, or have something you’d like to share, please reach out to research@thinkst.com.
1 comments On Meet “ZipPy”, a fast AI LLM text detector
Hey! Brilliant idea. I just have one question, shouldn’t the compression ratio be CR=1-compressed/original?